
La IA prometía intimidad, pero ha heredado las tuberías del AdTech

Hay una mentira piadosa que todos aceptamos cuando abrimos un chatbot de IA generativa: esto queda entre la máquina y yo. Já! No lo decimos así, claro… somos gente sofisticada que hablamos de productividad, asistencia, copilotos, agentes, workflows y todas esas palabras que hacen que una confesión íntima parezca una feature de SaaS. Pero, en la práctica, escribimos como si hubiera una cortina.
“¿Cómo preparo una negociación de despido?”
“¿Estos síntomas son graves?”
“¿Puedo optimizar fiscalmente esto sin meterme en problemas?”
“¿Cómo le digo a mi socio que quiero salir de la empresa?”
Antes estas preguntas iban al buscador, al abogado, al médico, al amigo discreto o al cuaderno que nadie debía leer, pero ahora se las damos a una interfaz amable, rápida y sorprendentemente paciente. El problema es que, según una investigación publicada por LeakyLM, con participación de investigadores de IMDEA Networks y recogida por Zero Party Data, esa cortina quizá tenía píxeles, cookies, APIs de conversión y algún que otro tercero sentado detrás tomando notas técnicas. ¡Qué bonito cuando la innovación mantiene vivas las tradiciones!
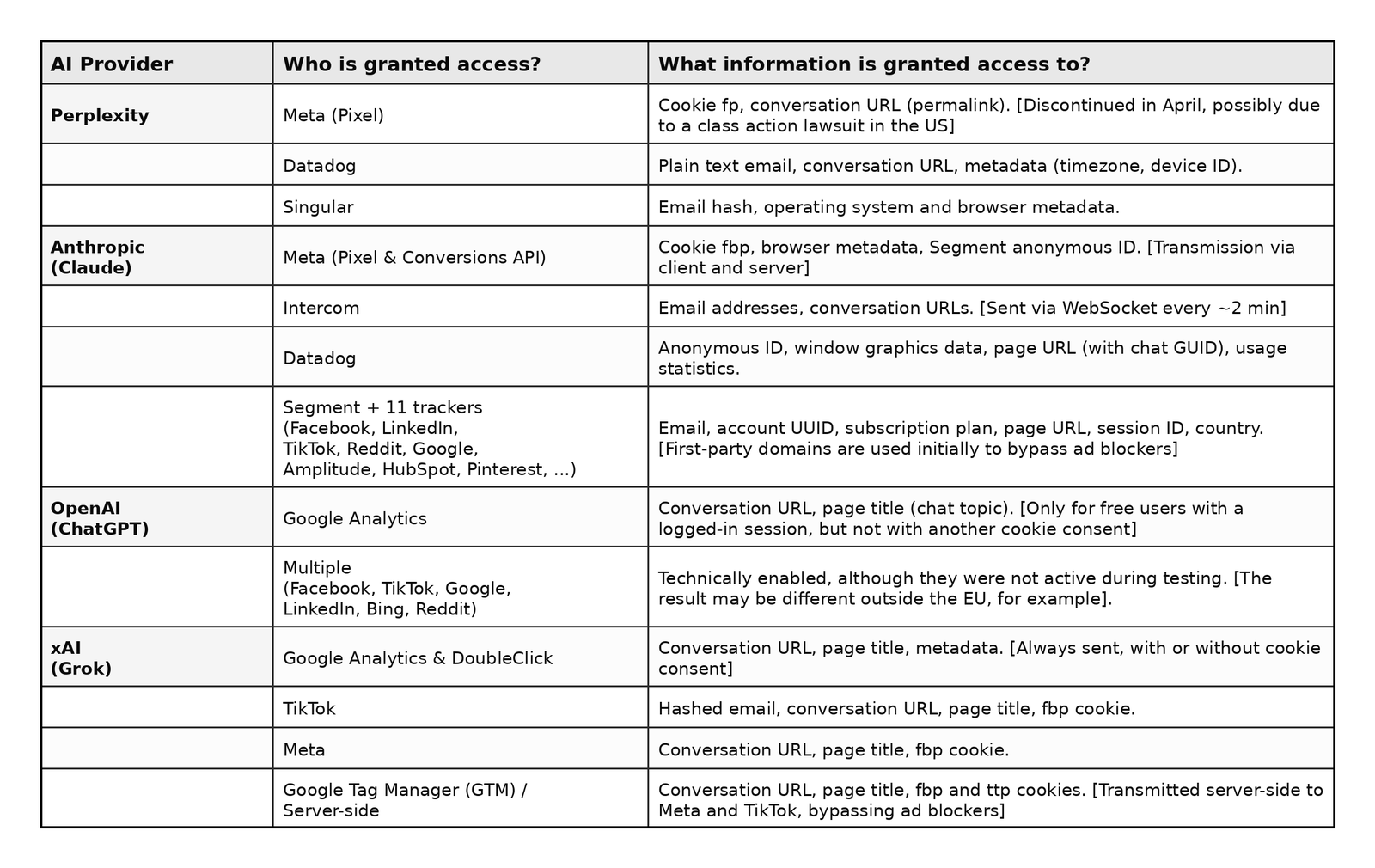
El hallazgo no debería leerse como una anécdota de privacidad para usuarios paranoicos. La investigación analiza las interfaces web de Perplexity, Claude, Grok y ChatGPT, y describe riesgos estructurales derivados de la presencia de trackers de terceros en servicios de IA generativa. El reporte afirma que se observaron envíos de URLs de conversación, títulos de chats, identificadores y metadatos hacia terceros como Google, Meta, TikTok, Intercom, Datadog o plataformas conectadas mediante APIs de conversión, dependiendo del proveedor, el estado de login, el consentimiento de cookies y otras condiciones técnicas. Los propios investigadores aclaran que no tienen evidencia de que esos terceros hayan leído efectivamente las conversaciones, sino de que ciertos datos quedaron accesibles o fueron transmitidos en determinadas condiciones. Esta diferencia importa y mucho, pero también debería importarnos que haya que hacerla.
El detalle aparentemente menor es el título de la conversación. Cualquiera que use IA sabe que el sistema suele titular los chats de forma automática y a veces, con una puntería que da más miedo que algunos modelos predictivos. “Depression tips”, “Aggressive tax deductions”, “They cheated on me, what do I do?” o “Unusual cough” son ejemplos citados en el análisis de Zero Party Data para explicar el problema: no hace falta acceder al prompt completo para inferir bastante. En publicidad digital llevamos años defendiendo que la inferencia no es lo mismo que el dato declarado, algo que es técnicamente cierto, pero comercialmente hemos vivido de hacer que esa diferencia sea lo más fina posible. Ahora esa lógica entra en un espacio donde el usuario no está mirando zapatillas, sino verbalizando ansiedad, enfermedad, miedo, dinero o conflicto.
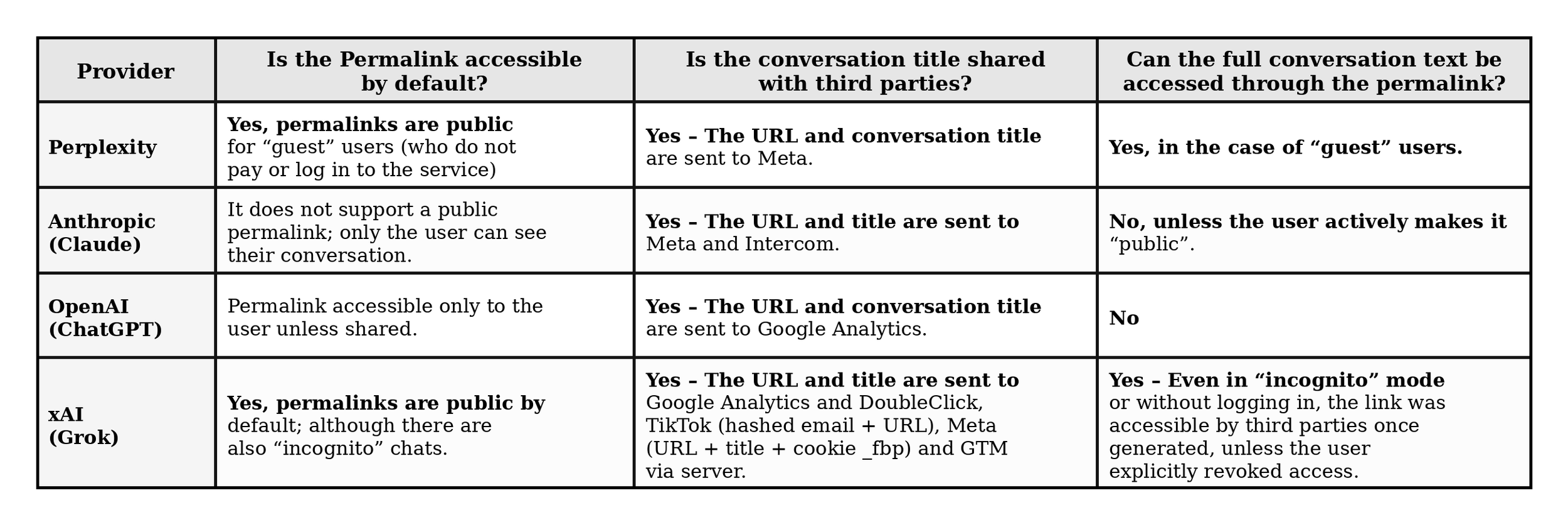
El segundo elemento es la URL. En algunos servicios, cada conversación tiene un permalink, una dirección estable que puede apuntar a un chat concreto. Según LeakyLM, en ChatGPT y Claude esos enlaces son visibles solo para el usuario salvo que se compartan explícitamente, mientras que en Grok las conversaciones eran accesibles por defecto y los chats guest eran públicos; Perplexity presentaba casuísticas específicas según nivel de usuario y configuración. La investigación también señala que, cuando la URL de una conversación se transmite a un tracker y el control de acceso del permalink es débil, la filtración deja de ser solo metadata y puede acercarse funcionalmente a compartir el contenido de la conversación. No es exactamente el mismo escenario en todos los proveedores, pero el patrón general es suficientemente incómodo: el enlace puede convertirse en la llave.
Aquí la industria publicitaria debería dejar de fingir sorpresa. Lo que aparece en esta investigación no es magia negra, es un repertorio conocido de sobra: píxeles, cookies persistentes, parámetros de URL, títulos de página, server-side tracking, APIs de conversión, first-party domains que suavizan la fricción con bloqueadores y consentimiento convertido en una especie de teatro interactivo. El reporte describe, por ejemplo, transmisión de URL y título de conversación a Google Analytics en ChatGPT para usuarios gratuitos logueados, integraciones de Claude con Intercom y forwarding server-side condicionado en algunos casos al consentimiento, y combinaciones de Google Analytics, DoubleClick, TikTok, Meta y GTM server-side en Grok bajo distintas condiciones. No es nuevo… y ese es precisamente el problema.
Desde siempre AdTech ha construido una habilidad extraordinaria que consiste en convertir señales sueltas en perfiles útiles: una visita por aquí, un evento por allá, una cookie, un hash de email, una URL, una categoría de contenido, una compra, una App, una localización aproximada, una audiencia lookalike vestida con traje de privacidad…. Luego llegó la IA conversacional y muchos pensaron que era otra categoría tecnológica cuando en realidad, puede ser algo más delicado: una nueva capa de entrada de datos donde el usuario no solo navega, sino que se explica. No busca “abogado laboral Madrid”, pregunta cómo afrontar una reunión con Recursos Humanos después de recibir una advertencia formal. No busca “tos seca”, describe síntomas, contexto familiar y miedo. No busca “crédito rápido”, cuenta que no llega a final de mes.
Este cambio altera la gravedad ética del tracking; en la web tradicional, muchas señales se interpretaban desde comportamiento observado, mientras que en los chatbots, el usuario aporta intención, contexto y vulnerabilidad en lenguaje natural. Para un ecosistema publicitario, esa diferencia no es ninguna tontería: un prompt puede condensar en una frase lo que antes requería semanas de navegación para aproximar y aunque el estudio no demuestre explotación publicitaria efectiva de esos datos por terceros, sí documenta una arquitectura donde partes de esa conversación, o sus identificadores, pueden entrar en contacto con infraestructuras diseñadas precisamente para medir, atribuir, perfilar y optimizar… es decir, con nuestra cocina.
La respuesta fácil sería culpar a las plataformas de IA, como si el AdTech estuviera observando desde fuera con cara de notario, pero eso no cuela. Si estas integraciones existen, existen porque el mercado ha normalizado que casi cualquier interfaz digital sea también una superficie de medición. La analítica tenía que estar, el píxel tenía que estar, la atribución tenía que estar, el retargeting quizá no, pero por si acaso, y cuando alguien preguntaba por privacidad, se añadía un banner, una política de 9.000 palabras y una promesa de control del usuario, que suena muy bien hasta que aparece el server-side tracking entrando por la puerta de servicio.
El análisis legal recogido por Zero Party Data apunta precisamente a ese punto: bajo GDPR, el problema no sería solo si un tercero accede o no al contenido, sino la base jurídica, la transparencia y la decisión de habilitar determinados flujos hacia terceros. Tenemos que recordar que informar de forma genérica no equivale a explicar de manera comprensible que pueden compartirse títulos, URLs o identificadores ligados a conversaciones con servicios de tracking. También es conveniente introducir la discusión sobre anonimización, pseudonimización y la llamada doctrina Scania, con una advertencia bastante clara: cuando los destinatarios potenciales son gigantes cuyo negocio consiste en combinar fuentes de datos, la idea de un riesgo insignificante de reidentificación merece algo más que una diapositiva tranquilizadora.
Para quienes trabajamos en publicidad digital, esta historia debería importarnos por tres razones: la primera es reputacional; la industria está intentando vender privacy-first, data clean rooms, consent mode, data collaboration y medición responsable. Pero si la IA conversacional acaba asociada a flujos opacos hacia trackers, el usuario no va a distinguir entre “la plataforma de IA”, “el partner analítico” y “el ecosistema publicitario”. Meterá todo en el mismo saco, y francamente, a veces le damos la cuerda nosotros. La segunda razón es estratégica: los chatbots serán interfaces comerciales, buscadores, asesores de compra, agentes de viaje, recomendadores financieros y capas de atención al cliente. Si esas interfaces nacen con la misma lógica de tracking acumulativo que la web abierta, la batalla regulatoria no va a tardar años en llegar, puede llegar antes de que los modelos de negocio maduren. La tercera razón es más incómoda: tal vez la promesa de la IA como nuevo canal publicitario dependa menos de inventar formatos y más de demostrar contención, no más targeting pero sí mejor arquitectura.
La conocida frase “cuando algo es gratis, el producto eres tú” se queda corta aquí. En un chatbot, el producto no es solo tu atención, es tu relato y el relato, cuando se titula solo, se guarda en una URL y viaja con identificadores, empieza a parecer demasiado útil para demasiada gente.
La IA tendrá publicidad de una forma u otra, así que pregúntate si vamos a construirla con límites verificables o con la misma vieja fé en que nadie mirará demasiado dentro de las tuberías… porque ya sabemos cómo acabó la primera vez.
Puntos clave:
Una investigación de IMDEA Networks señala que servicios como ChatGPT, Claude, Grok y Perplexity incorporan trackers de terceros que pueden recibir URLs de conversación, títulos de chats y otros metadatos sensibles.
El riesgo no está solo en el contenido literal del prompt, sino en la combinación entre títulos, permalinks, cookies, identificadores y plataformas publicitarias capaces de reconstruir contexto.
Para la publicidad digital, el caso abre una pregunta: si la IA conversacional adopta la infraestructura del AdTech clásico, ¿estamos construyendo una nueva interfaz de confianza sobre los mismos incentivos de siempre?
Este resumen lo ha creado una herramienta de IA basándose en el texto del artículo, y ha sido chequeado por un editor de PROGRAMMATIC SPAIN.