
Algo no funciona con las Conversion API's
Desde hace algunos años, las marcas y las agencias tienen un mandato implícito: si quieres medir, optimizar y sobre todo atribuir, tienes que enviarle “conversiones” a cada plataforma en la que inviertes. Y así, entre píxeles, SDKs y APIs, nació un monstruo llamado “Conversion API”, también conocido como CAPI.
Lo que comenzó como un mecanismo útil para capturar eventos offline (como por ejemplo compras en tienda) y devolverlos a los Walled Gardens, se ha transformado en un estándar un tanto difuso, algo así como una suerte de pegamento universal que nadie cuestiona pero que todos sufren. Como muchas soluciones en esta industria, se ha vuelto omnipresente, y paradójicamente, poco eficiente y su proliferación ha sido más una consecuencia de la urgencia que del diseño.
Este artículo no es una crítica, ni una queja más de lo que suponen las implementaciones de los CAPI sino una mirada estructural sobre por qué el modelo actual quizá no es el mejor y qué alternativas reales pueden existir para poder reemplazarlo, porque si algo está claro, es que no podemos seguir escribiendo conversiones decenas de veces, para decenas de plataformas, con decenas de formatos distintos. El sistema necesita un write once, read many, y lo necesita ya.
¿Qué es CAPI y cómo hemos llegado hasta aquí?
El Conversion API nació en los gigantes digitales (léase Meta, Google, TikTok) como un método Server-To-Server que permitía a los anunciantes enviar eventos directamente desde sus sistemas backend. El objetivo era muy simple: sortear las restricciones de los navegadores, las limitaciones de los píxeles client-side y la pérdida de señales que traería la desaparición de las cookies. Como idea no era mala, pero como suele pasar en nuestro sector las buenas ideas se desvirtúan al escalar sin consenso ni estándares. Hoy en día CAPI se utiliza para todo: conversiones online, eventos offline, medición, atribución, optimización, audiencias... y lo peor de todo, cada plataforma lo implementa a su manera.
Y es que hoy en día, un anunciante que tenga presencia multicanal debe tener múltiples integraciones CAPI, cada una es una “tubería” independiente: con su autenticación, su esquema, su mantenimiento. Y lo malo es que no hay estándar, por lo que no hay eficiencia… y el resultado es un caos de tuberías, donde cada conversión debe ser “empujada” a cada destino. Este modelo tiene tres problemas fundamentales:
1. Multiplicación de integraciones y costes: Cada nueva plataforma significa una nueva API, un nuevo esfuerzo técnico. Para una PYME quizás sea manejable, pero para una multinacional con decenas de partners y millones de eventos diarios, es un infierno operativo. A esto se suman los cambios constantes en las especificaciones, nuevas versiones y/o métodos de autenticación. ¿Resultado? Equipos de data engineering atados a tareas repetitivas, sin tiempo para análisis reales, por no hablar de los costes.
2. Copias redundantes de datos: Cada vez que se envía un evento de conversión, se crea una copia. ¿Una para Meta? Check. ¿Otra para Google? Check. ¿TikTok? También. ¿The Trade Desk, Amazon, Pinterest? Todas necesitan su propia “copia”. Esto no solo es ineficiente, sino que es insostenible, desde el punto de vista del proceso de datos, del almacenamiento, y aunque cada vez más… se nos olvide el impacto medioambiental. ¿Cuántos ciclos de CPU, almacenamiento y transferencias innecesarias están consumiendo estos duplicados? La industria que se jacta de ser “data-driven” debería empezar por ser “data-efficient”.
3. Un modelo no centrado en la privacidad: Aunque CAPI se presenta como más privacy-friendly que las cookies, la realidad es más ambigua: en la práctica, este modelo “push” implica enviar datos sensibles a múltiples terceros, pero ojo, incluso con hashing o pseudonimización, los riesgos aumentan con cada copia y cada destino. Es cierto que en algunos casos no existe alternativa alguna: para que una plataforma optimice, necesita los eventos, pero el modelo actual sigue siendo una lluvia de datos sin controles finos, sin trazabilidad clara, y sin un marco común de gobernanza.
¿Cuál es la solución? Replantear desde los datos, no desde las APIs
Lo que tenemos no es un problema de marketing, sino de ingeniería de datos. La lógica debería ser simple: los anunciantes deberían escribir sus conversiones una sola vez, en un lugar seguro y gobernado, y los distintos partners deberían poder leerlas de forma controlada, eficiente y auditable. Este modelo ya existe en otras industrias. Se llama data sharing y en el ecosistema de Snowflake, ya es una realidad.
Veamos un caso real: The Trade Desk y REDS. The Trade Desk comparte sus logs de impresiones (REDS) con los anunciantes vía Snowflake Data Sharing. No hay archivos CSV, no hay APIs intermedias. El anunciante accede directamente, sin mover los datos, sin duplicarlos, en tiempo real. Inspirándose en este modelo, algunos anunciantes están empezando a dar el paso inverso: en vez de empujar conversiones a cada partner, comparten una tabla de conversiones central desde su data warehouse. Los partners acceden a ella con permisos explícitos, sin copias, sin fricción.
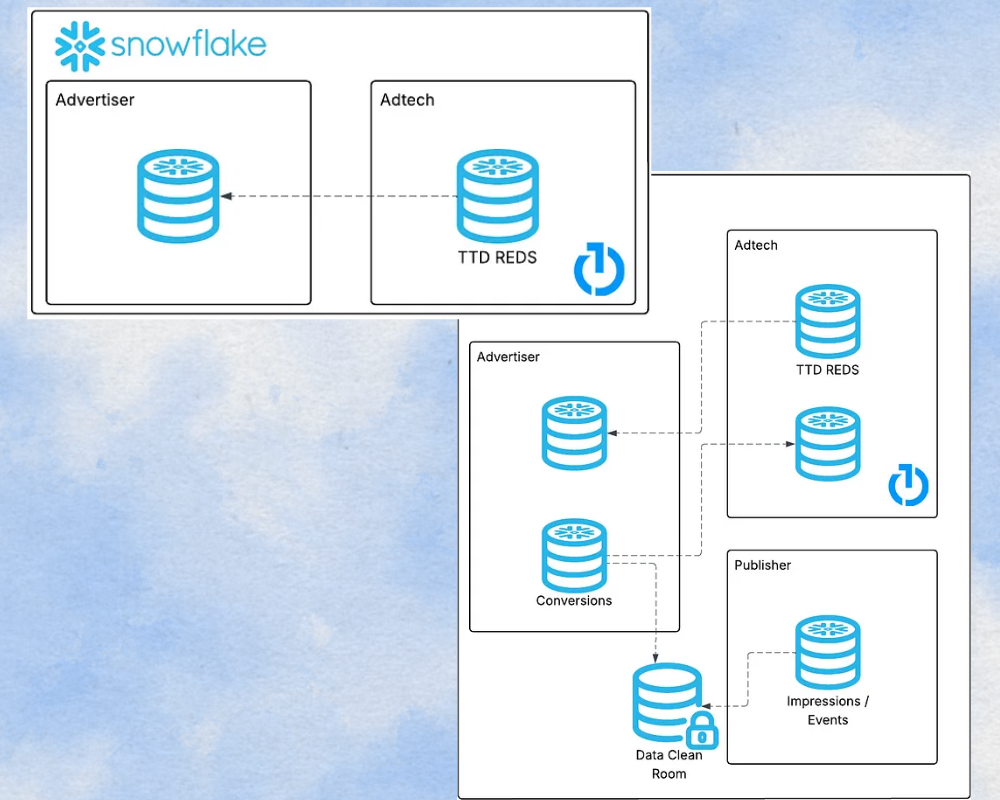
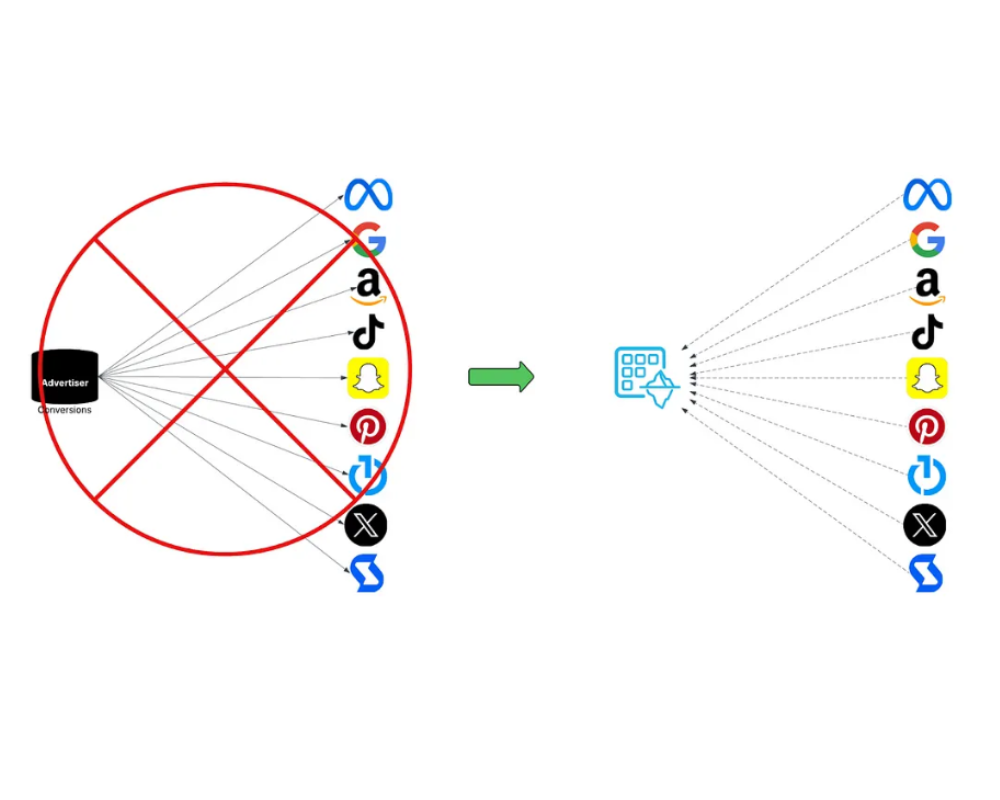
¿Por qué es mejor?
Este modelo de “escribo una vez y comparto muchas” tiene beneficios evidentes:
Eficiencia técnica: menos pipelines, menos código, menos mantenimiento.
Privacidad y gobernanza: accesos controlados, auditabilidad, minimización de datos.
Escalabilidad: manejo de grandes volúmenes sin redundancias.
Interoperabilidad con Data Clean Rooms: las mismas tablas se pueden usar para Data Clean Rooms, sin rehacer procesos.
Pero no es perfecto… Hay dos grandes problemas que frenan su adopción masiva:
No todo el mundo está en Snowflake. Aunque Snowflake lidera en data sharing, hay plataformas en BigQuery, Redshift o sistemas propietarios, por lo que sin un estándar abierto y cloud-neutral, el avance será desigual.
Los publishers siguen siendo conservadores. Muchos reciben los datos vía sharing… y luego los usan para llamar a su propio endpoint CAPI. Es decir, el modelo mejora la entrega, pero no cambia la lógica de fondo.
¿El futuro?: "conversions.txt" o Conversions Table
Algunos proponen soluciones sencillas, como un archivo conversions.txt en S3 que cada partner pueda consultar. La idea recuerda al ads.txt, pero aplicado a conversiones. En teoría funciona, pero en la práctica es inviable. Los CSVs no escalan, no permiten gobernanza, ni control de accesos, ni transacciones: no son un sistema de datos, sino un parche. La solución real puede ser mantener una Iceberg Table en cloud storage, accesible para todos los partners autorizados. Por ejemplo Apache Iceberg permite construir tablas abiertas, escalables, con versionado, gobernanza y performance. Es el camino hacia un estándar de shared conversions, interoperable y limpio.
Mañana publicaremos una segunda parte del artículo con los detalles técnicos del modelo basado en Apache Iceberg ya que el modelo actual de CAPI está prácticamente agotado: fragmentado, redundante, caro y con muchos riesgos. Seguir por este camino es una decisión de inercia, no de estrategia. Los anunciantes necesitan recuperar el control, centralizar sus datos, compartirlos de forma segura y exigir a sus partners (sí, también a los gigantes) que se adapten a un modelo más moderno, eficiente y respetuoso con la privacidad. La tecnología existe pero el cambio no será inmediato, pero sin duda será inevitable, y como siempre en esta industria quienes lo adopten primero tendrán ventaja.
La próxima gran disrupción no vendrá de un nuevo algoritmo sino del rediseño de las bases de datos compartidas. Es hora de dejar de empujar eventos. Es hora de construir infraestructuras abiertas.
Puntos clave:
El sistema CAPI actual está acabado: Multiplica esfuerzos, copias de datos y riesgos de privacidad en cada integración.
La solución es un modelo write once, read many: Usar tablas Iceberg compartidas entre anunciantes y publishers reduce fricción, costes y duplicaciones.
Apache Iceberg es una tecnología clave: Ofrece versionado, gobernanza, escalabilidad y compatibilidad multi-cloud para construir un nuevo estándar de compartición de conversiones.
Este resumen lo ha creado una herramienta de IA basándose en el texto del artículo, y ha sido chequeado por un editor de PROGRAMMATIC SPAIN.