
Del dato al sistema: así se está reordenando el nuevo stack del marketing inteligente

Hay una forma bastante útil de leer lo que está ocurriendo en martech sin quedarse atrapado en el ruido de producto, en las etiquetas de moda o en el desfile diario de “soluciones con IA”. Consiste en mirar menos el claim comercial y más la arquitectura que se está imponiendo por debajo, y la arquitectura que empieza a consolidarse tiene cuatro capas bastante claras:
En la base, las fuentes de First-Party Datay la infraestructura. Encima, una capa de deep learning orientada a descubrir patrones y segmentos no obvios. Después, una capa de contexto, razonamiento e inteligencia accionable que traduce la matemática en decisiones utilizables por negocio; y, por último, una capa de activación y ejecución cada vez más conectada con APIs, automatizaciones y sistemas agénticos.
Esta secuencia importa porque cambia la lógica de valor de todo el ecosistema. Durante la última década, gran parte de la industria vendió modernización de marketing como si consistiera en centralizar datos, levantar dashboards, modelar atribución y empujar segmentos a plataformas de activación: no era falso, pero se ha quedado corto. El problema del viejo stack es que estaba diseñado para ver mejor, no necesariamente para decidir mejor. La medición servía para ordenar el pasado, pero el nuevo discurso del mercado intenta monetizar otra cosa: la capacidad de encontrar oportunidades que no son evidentes a simple vista y de convertir ese hallazgo en una acción concreta.
La primera capa ya no diferencia tanto
La base de cualquier arquitectura sigue siendo el First-Party Data. Data warehouses, lakes, clouds, pipelines, gobernanza, taxonomías, resolución de identidades, normalización de señales… Todo esto sigue siendo imprescindible, pero también empieza a parecerse cada vez más a infraestructura mínima, no a ventaja competitiva sostenida. Tener los datos ordenados sigue siendo difícil; lo que ya no resulta creíble es presentarlo como final del viaje. En muchas empresas, esa capa empieza a comportarse como requisito de entrada. Este desplazamiento es importante para anunciantes, consultoras, agencias y vendors porque obliga a reconocer algo complicado: buena parte de lo que se vendió como transformación en los últimos años era en realidad, preparación, necesaria, sí… diferencial, cada vez menos.
El nuevo frente está en discovery
La segunda capa es donde el relato se vuelve más interesante. Aquí no se trata solo de agrupar usuarios o de replicar una segmentación clásica con otro nombre, sino que se trata de usar modelos para detectar estructuras menos obvias dentro del dato de cliente: cambios de valor, propensión, recuperabilidad, afinidades latentes, señales tempranas de churn, comportamientos que no emergen en un informe tradicional. Esta transición del reporting al discovery es, probablemente, una de las mutaciones más relevantes del stack actual porque desplaza el centro de gravedad desde la lectura del pasado hacia la exploración de lo que el sistema todavía no ha capturado como decisión.
Conviene, eso sí, evitar la grandilocuencia. Esta capa no es trivial: requiere una ingeniería de datos seria, feature engineering, etiquetado, entrenamiento, iteración, validación y acceso a capacidad de cómputo suficiente. No basta con tener un entorno cloud y una base de datos razonablemente ordenada. Aquí es donde muchas promesas de IA empiezan a quedarse sin suelo, porque entre decir “hacemos discovery” y hacerlo con utilidad operativa hay un tramo largo, costoso y bastante menos sexy que una demo. En ese tramo viven la mayoría de los cuellos de botella reales del mercado.
Del modelo a la decisión: la capa más codiciada
La tercera capa es, probablemente, la más estratégica de todas y no porque sea la más visible, sino porque es la que traduce el output técnico en lenguaje de negocio. Un modelo puede detectar patrones valiosos, pero otra cosa es convertir esos patrones en una recomendación entendible, defendible y alineada a KPI. Aquí entran en juego los modelos de lenguaje, los sistemas de razonamiento, las capas semánticas, la lógica de negocio y la interfaz, pero conviene no simplificarlo como si bastara con poner un LLM encima de unas tablas y esperar que aparezca la inteligencia. El valor real de esta capa no está solo en explicar, está en opinar operativamente, es decir, en priorizar, contextualizar, conectar el hallazgo con una métrica de negocio y reducir la distancia entre complejidad analítica y decisión humana. En términos de poder dentro del stack, esta es la capa que más gente quiere controlar ahora mismo… y se entiende por qué. La infraestructura de abajo tiende a comoditizarse. La activación de arriba está muy disputada y, en muchos casos, depende de plataformas externas, pero la capa que convierte señal en criterio es otra cosa: esa capa puede volverse indispensable.
La activación ya no es solo mandar audiencias
La cuarta capa también está cambiando. Durante años, el final lógico del proceso era relativamente estable: construir un segmento, exportarlo a Meta, Google, un DSP, un ESP o un entorno de personalización, y optimizar desde ahí. Ese final ya no parece suficiente. Lo que empieza a pedirse ahora es que el dato y la inteligencia generada puedan circular también hacia sistemas automatizados, flujos agénticos, conectores más ricos, entornos server-side y capas de ejecución que no responden solo a una campaña, sino a un sistema continuo de decisión. Esto tiene implicaciones profundas tanto prácticas como políticas. Prácticas, porque obliga a repensar cómo se empaqueta y expone la información para ser utilizable por otros sistemas. Políticas, porque cambia quién controla la activación y quién se queda con la visibilidad del rendimiento. Cuanto más automatizado se vuelve el stack, más relevante se vuelve la calidad de lo que entra en la máquina y más opaca puede volverse la cadena de decisión para quienes están fuera de ella.
Lo que esto cambia para agencias, anunciantes y vendors
La lectura fácil sería decir que estamos entrando en una era más inteligente del marketing, pero la lectura seria exige más cautela. Lo que realmente está ocurriendo es una redistribución del valor: parte del presupuesto y del poder que antes se justificaba en reporting, integración o activación básica puede desplazarse hacia quienes prometan descubrir mejor, contextualizar mejor y ejecutar en sistemas más cerrados y más automatizados.
Para las agencias, esto no significa desaparición sino desplazamiento: menos tiempo dedicado a traducir dashboards y más presión para entender arquitectura de datos, calidad de señal, inferencia de negocio, activación server-side y gobernanza operativa.
Para los anunciantes, la promesa tampoco es neutral. Cuanto más sofisticada es la capa intermedia que une modelo, contexto y activación, más difícil puede resultar cambiar de proveedor, auditar decisiones o separar qué parte del rendimiento viene del dato, cuál del modelo y cuál de la propia plataforma.
Para los vendors, en cambio, el incentivo es evidente: ya no basta con ser una pieza del stack, hay que aspirar a ser la pieza que da sentido al resto.
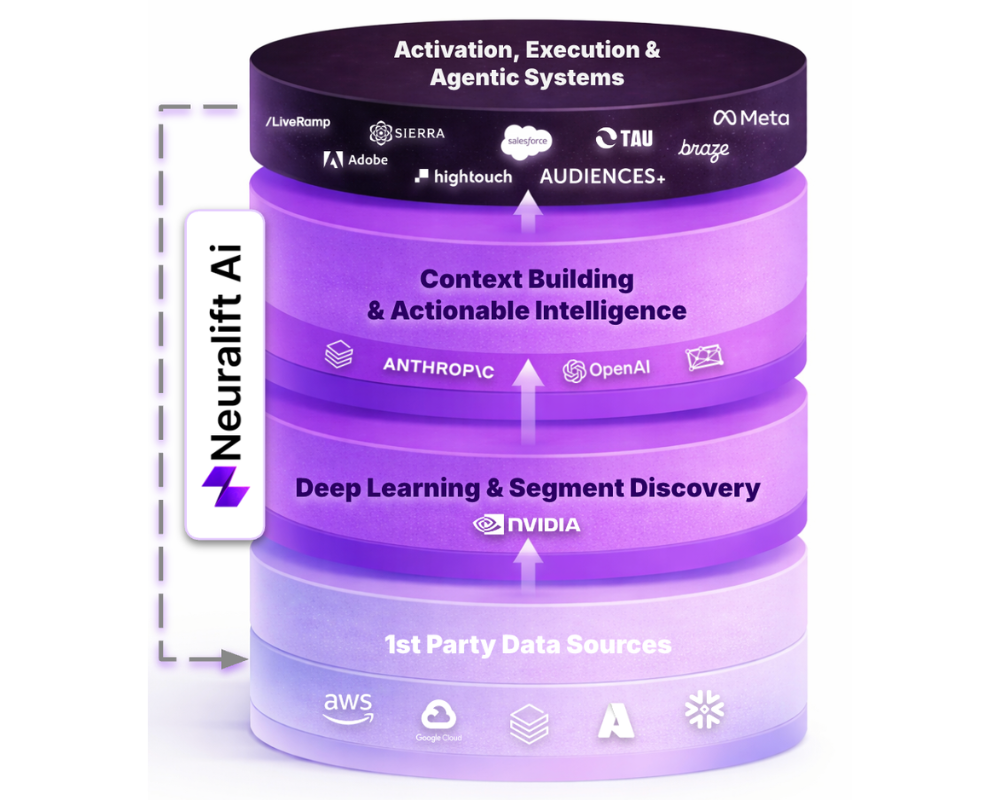
Un ejemplo visual de la tesis que viene
La imagen adjunta (Neuralift Ai) resume bastante bien esta lógica, aunque de forma interesada y corporativa, como suele ocurrir en este tipo de diagramas. El esquema divide el stack en cuatro pisos: fuentes de datos propias en la base, deep learning y discovery encima, una capa de contexto e inteligencia accionable a continuación, y una última de activación, ejecución y sistemas agentic en la parte superior. Lo interesante de este gráfico no es quién aparece en cada capa, sino el mensaje que deja entrever: la infraestructura sola ya no basta, la activación sola tampoco, y el valor aspiracional se concentra en las capas intermedias donde el dato se transforma en señal útil y después en decisión. Ese tipo de representación se está usando ya en el mercado como forma de explicar nuevas propuestas de valor. Algunas empresas lo presentan con nombre propio y ocupando las capas centrales del modelo, como pieza de posicionamiento, tiene lógica y como señal de mercado, también porque cuando varios actores empiezan a dibujar el mismo mapa, aunque se coloquen a sí mismos en el centro, normalmente no estamos ante una moda aislada, sino que estamos viendo cómo se está intentando fijar el nuevo lenguaje de poder del sector.
El cambio de fondo no es tecnológico, es estructural
La industria suele enamorarse demasiado rápido de los acrónimos: antes eran los CDPs, luego llegaron las Data Clean Rooms, más tarde los copilots, ahora los agentes… pero el cambio que importa no está en la etiqueta concreta. Lo que de verdad está cambiando es la función del dato de cliente dentro del sistema: pasa de ser un activo para observar a ser un activo para descubrir y en cuanto el dato cambia de función, cambia también el tipo de software que se considera estratégico, el tipo de talento que gana peso y el tipo de dependencia que el mercado empieza a aceptar como normal.
Eso debería interesar mucho a nuestros lectores de PROGRAMMATIC SPAIN porque la programática, entendida en sentido amplio, siempre ha sido una industria de decisión automatizada. Lo que viene ahora no elimina esa lógica, la profundiza, pero lo hace desplazando parte del valor fuera del media buying puro y hacia capas previas de modelado, razonamiento y orquestación.
La conclusión de todo esto es muy sencilla: el próximo stack no se va a disputar solo en el inventario, ni en el dashboard, ni en la nube, se va a disputar en la capa que decide qué significa el dato y qué acción merece. En publicidad digital, quien controla esa traducción no solo vende tecnología, condiciona la estrategia.
Puntos clave:
El mercado se está desplazando desde una lógica de medición hacia una lógica de descubrimiento: el dato ya no se usa solo para explicar qué pasó, sino para orientar qué hacer después.
El nuevo stack no se define únicamente por almacenamiento, reporting o activación, sino por dos capas intermedias cada vez más valiosas: descubrimiento algorítmico y traducción de ese output en inteligencia accionable.
La batalla real no será por quién tiene más dashboards, sino por quién controla la capa que convierte datos propios en decisión operativa, contexto de negocio y activación automatizada.
Este resumen lo ha creado una herramienta de IA basándose en el texto del artículo, y ha sido chequeado por un editor de PROGRAMMATIC SPAIN.