
Diferencias entre Data Science, Inteligencia Artificial, Machine Learning y Deep Learning
En este artículo intentaremos arrojar luz sobre cada uno de los siguientes términos uno por uno:
Data Science
Inteligencia Artificial
Machine Learning
Deep Learning
Cuando termines de leer esta publicación, tendrás una idea bastante clara de lo que significan estos términos y cómo se diferencian o se relacionan entre sí.
Empecemos con un diagrama de Venn en que se puede visualizar esta terminología relacionada con la IA de manera superpuesta.

1. Data Science
El Data Science (o “ciencia de los datos” en castellano), como su nombre indica, trata sobre los datos. Es un campo multidisciplinario centrado en extraer INFORMACIÓN (insights) que puede ayudar a una empresa a tomar mejores decisiones.
Por ejemplo, si un banco analiza los datos recopilados en sus múltiples plataformas, puede descubrir qué clientes son solventes (o insolventes) o identificar qué productos financieros son los que están comprando los nuevos clientes.
Hoy en día, la disponibilidad de grandes volúmenes de datos implica más ingresos debido a Data Science. Con el análisis predictivo, es posible identificar patrones ocultos en datos que ni siquiera sabías que existían. Por ejemplo, una empresa de viajes online puede descubrir que las personas que viajan con aerolíneas estadounidenses a Ámsterdam optan por un lujoso crucero por los canales de la ciudad. Usando análisis prescriptivo, la empresa puede aprender además que las personas que vuelan en Business prefieren un crucero nocturno, mientras que aquellos que vuelan en clase económica reservan recorridos en bicicleta. Esta información basada en datos puede ser extremadamente valiosa para la publicidad dirigida o para las estrategias de venta cruzada (cross-selling).
Las empresas usan el Data Science de diferentes maneras. A continuación, se muestran algunos ejemplos de aplicaciones:

Quizás te preguntes por qué algunas aplicaciones de Data Science te recuerdan a aplicaciones de inteligencia artificial. Bueno, esto se debe a que Data Science se superpone al campo de la inteligencia artificial en muchas áreas. Un científico de datos (Data Scientist) utiliza herramientas como modelos estadísticos, métodos de visualización, pruebas de hipótesis y algoritmos de aprendizaje automático (la IA también utiliza el aprendizaje automático). Un producto típico deData Science se basa en la aplicación de conocimientos en diferentes campos, como se muestra en la imagen siguiente:

En esta publicación en inglés podrás entender en qué consiste brevemente el Data Science Pipeline para comprender cómo los científicos de datos construyen modelos aplicando algoritmos de aprendizaje automático en los datos (no es necesario tener conocimientos previos en ese campo).
2. Inteligencia Artificial (IA)
Para entender qué es la IA, es importante comprender el contexto histórico. El concepto de IA ha existido desde la antigüedad: han habido numerosos mitos e historias de objetos inanimados dotados de inteligencia por expertos artesanos.
Las semillas de la IA moderna, sin embargo, fueron plantadas por los filósofos clásicos que intentaron describir el pensamiento/inteligencia humanos como un sistema simbólico. La computadora digital programable, la máquina basada en el razonamiento matemático abstracto, se inventó por primera vez en la década de 1940 basándose en este trabajo.
El término "Inteligencia Artificial" fue acuñado por John McCarthy, un ingeniero informático en 1955. La investigación en IA moderna comenzó formalmente en 1956 en un taller en Dartmouth College, una universidad privada de investigación de la Ivy League en New Hampshire, Estados Unidos.

Algunos de los asistentes al taller de IA en 1956 (Fuente de la imagen: thedartmouth.com)
La investigación de la IA en ese momento se centró en las redes neuronales, inspirada en la forma en que funcionan las neuronas en el cerebro humano. Las personas que asistieron a este taller más tarde se convirtieron en líderes en el campo.
Hasta la década de 1970, el campo estaba en auge con los descubrimientos, pero estaban lejos de crear máquinas inteligentes. Inicialmente, esperaban que existiera una máquina tan inteligente como un ser humano en la década de 1980 que pudiera leer y comprender el mundo que nos rodea, y razonar como nosotros. Pero construir máquinas con inteligencia artificial no fue tan simple. Las limitaciones en la potencia de procesamiento de la computación también obstaculizaron el progreso de la IA. Durante muchas décadas, la IA se limitó a los laboratorios de investigación.
El Machine Learning (o aprendizaje automático) se hizo más popular desde finales de la década de 1980 hasta la década de 2010. La financiación y el interés en la inteligencia artificial alcanzaron su punto máximo a principios de la década de 2000 cuando los grandes gigantes tecnológicos comenzaron a construir superordenadores e invertir en inteligencia artificial. El Deep Learning (o aprendizaje profundo) se convirtió en el punto focal para los investigadores de IA de todo el mundo.
La siguiente imagen muestra la evolución de la IA durante las últimas décadas:

La IA todavía está en evolución y se considera un término realmente amplio. Machine Learning y Deep Learning son subconjuntos de la Inteligencia Artificial.
No existe una definición única para la IA. Se puede decir que la IA es la capacidad que podemos dotar a una máquina para permitirla:
Comprender / interpretar datos
Aprender de los datos
Tomar decisiones "inteligentes" basadas en conocimientos y patrones extraídos de los datos.
Una máquina impulsada por IA puede mejorar su capacidad basándose en "datos nuevos" que no formaban parte del conjunto de datos que se utilizó por primera vez para entrenarla. Por ejemplo, un sistema de video-vigilancia CCTV con tecnología de inteligencia artificial para monitorizar las infracciones de las señales de tráfico puede mejorar su capacidad para detectar infracciones sobre la base de nuevas imágenes de cámaras y las correspondientes multas de infracción de tráfico.
En un nivel fundamental, la IA es una colección de algoritmos matemáticos que permiten a los ordenadores comprender la correlación entre varios elementos de datos. En el ejemplo del sistema de vigilancia de antes, los datos recopilados y analizados en tiempo real pueden estar relacionados con los semáforos, los intermitentes, la posición de los vehículos en un semáforo, los carriles de tráfico, la distancia entre los vehículos, etc. para llegar a una conclusión procesable, es decir, determinar una infracción por saltarse una señal de tráfico y emitir una multa de manera automática.
En ese sentido, una máquina impulsada por IA realiza tareas imitando la inteligencia humana, pero a menudo, la IA va más allá de lo humanamente posible.
3. Machine Learning
El término Machine Learning (ML) fue acuñado por Arthur Samuel en 1959.
ML es un subconjunto de AI. Se utiliza en escenarios en los que necesita que las máquinas aprendan de grandes volúmenes de datos. El conocimiento así adquirido se aplica a un nuevo conjunto de datos. ML le da a una máquina la capacidad de aprender de (o acerca de) conjuntos de datos más nuevos sin dar instrucciones explícitas.
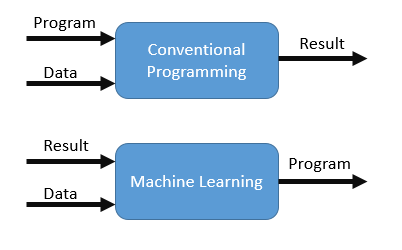
Se puede decir que ML es la implementación o aplicación actual de la IA. Algunos de los métodos más comunes implementados para "hacer que las máquinas aprendan" son:
Aprendizaje supervisado
Aprendizaje no supervisado
Aprendizaje automático reforzado
En algunos métodos, a la máquina se le informa de antemano acerca de las variables independientes (entrada) y dependientes (salida). La máquina aprende la relación entre estos dos tipos de variables analizando un conjunto de datos denominado "conjunto de datos de entrenamiento". Antes de entrenar un modelo de datos, se llevan a cabo una serie de pasos de pre-procesamiento de datos.
Una vez que una máquina ha sido "entrenada" lo suficiente o cuando un modelo de ML está listo, se aplica a un nuevo conjunto de datos, denominado "conjunto de datos de prueba".
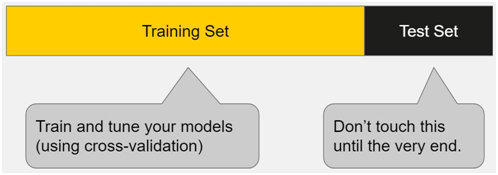
Fuente de la imagen: elitedatascience.com
El modelo ML entra en modo de producción solo después de que se haya probado lo suficiente para su fiabilidad y precisión.
ML implica el uso de varios algoritmos como regresión lineal simple, regresión de árbol de decisión, regresión polinomial, “vecinos más cercanos K”, etc. Los algoritmos de ML se pueden utilizar para abordar problemas de regresión, problemas de predicción, problemas de clasificación, etc.
Dado que las bibliotecas de aprendizaje automático (por ejemplo, SciKit) han evolucionado mucho en los últimos años, incluso los programadores sin experiencia en estadísticas o formación en inteligencia artificial pueden comenzar a usar estas bibliotecas para construir, entrenar, probar e implementar modelos de aprendizaje automático. Sin embargo, siempre es útil saber cómo funcionan exactamente los diferentes algoritmos de ML para que comprenda completamente lo que está haciendo.
4. Deep Learning (DL)
Puedes ver el DL como un subconjunto o un avance del ML. DL entra en juego cuando ML no puede ofrecer completamente los resultados deseados, si bien generalmente, ML es adecuado cuando su conjunto de datos es relativamente pequeño y es la opción preferida cuando:
Los datos tienen demasiadas características
Los datos son enormes
Se requiere un nivel de precisión extremadamente alto
En comparación con ML, DL puede resolver problemas más complejos, pero es más difícil de implementar, ya que requiere hardware especializado (por ejemplo, GPU’s) para ejecutarse y requiere más tiempo para entrenar el modelo (DL utiliza modelos de redes neuronales para comprender una gran cantidad de datos.)
Siri, Alexa o Google Assistant son algunas aplicaciones que usan DL para comprender tus solicitudes. Cuando Facebook reconoce a tus amigos en una imagen o Netflix te recomienda el tipo de películas que ver, son ejemplos de DL aplicado a un producto comercial.
Desde los agregadores de noticias, pasando por la detección de fake news hasta los automóviles autónomos, el procesamiento del lenguaje natural (NLP), el reconocimiento visual y los asistentes virtuales, las aplicaciones basadas en DL se están implementando en muchas áreas actualmente.
Los avances en DL están impulsando el auge de la inteligencia artificial. Entonces, sí, el DL es uno de los temas más candentes del momento.
Artículo original publicado en inglés en AI.PlainEnglish